Spark – Lightning-Fast Cluster Computing

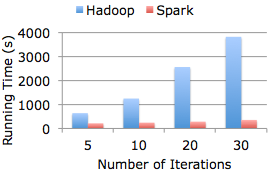
Spark is an open source cluster computing system that aims to make data analytics fast — both fast to run and fast to write. To run programs faster, Spark provides primitives for in-memory cluster computing: your job can load data into memory and query it repeatedly much quicker than with disk-based systems like Hadoop MapReduce. To make programming faster, Spark integrates into the Scala programming language, letting you manipulate distributed datasets like local collections. You can also use Spark interactively to query big data from the Scala interpreter.
More details and downloads can be found on the Spark homepage.
Projects
- Akaros - An operating system for many-core architectures and large-scale SMP systems
- Alluxio (formerly Tachyon), a Memory Speed Virtual Distributed Storage System
- BLB: Bootstrapping Big Data
- Cancer Tumor Genomics: Fighting the Big C with the Big D
- Carat - Collaborative Detection of Energy Bugs
- CoCoA: A Framework for Distributed Optimization
- Concurrency Control for Machine Learning
- CrowdDB - Answering Queries with Crowdsourcing
- DFC -- Divide-and-Conquer Matrix Factorization
- DNA Processing Pipeline
- DNA Sequence Alignment with SNAP
- GraphX: Large-Scale Graph Analytics
- KeystoneML
- MDCC: Multi-Data Center Consistency
- Mesos - Dynamic Resource Sharing for Clusters
- MLbase: Distributed Machine Learning Made Easy
- PIQL - Scale Independent Query Processing
- Real Life Datacenter Workloads
- SampleClean: Fast and Accurate Query Processing on Dirty Data
- Shark: SQL and Rich Analytics at Scale
- Spark - Lightning-Fast Cluster Computing
- SparkNet
- Sparrow: Low Latency Scheduling for Interactive Cluster Services
- Splash: Efficient Stochastic Learning on Clusters
- Succinct: Enabling Queries on Compressed Data
- Velox: Models in Action
